
Caching is one of the important and commonly used performance technique for low-latency responses from APIs.
A cache is a high-speed memory that persists frequently accessed but less frequently changing data. Using a cache reduces processing time for APIs as the data is readily available for it to fetch and use.
In this article, let’s look at an implementation of Distributed Cache with SQL Server as a backing store for data. We’ll look at how we can simply setup an SQL Server backing store and use IDistributedCache implementation for caching operations.
Limitations of an In-Memory Cache
The simplest implementation of a cache is in-memory caching, where data is stored within the application memory. This is a simple approach, but comes with two important limitations —
- Since data is persisted within the application memory, hence it is prone to loss when application restarts
- Since data is local to an application Node, which means in a multi-node environment duplication might occur (different nodes caching same data)
What is Distributed Caching?
Distributed Caching is a concept that overcomes these two limitations with its design. A Distributed Cache is a cache that is placed external to the application nodes, with the same properties as that of an in-memory cache – high speed memory with low-latency data reads and writes.
Since the cache is now external to application Nodes, it is independent of application Node crashes and data cached by one node can be accessed by other nodes. This removes any scope for data duplication and memory wastage on the same data.
Every Distributed Cache implementation requires a data store where the data can be persisted.
There are several popular providers in the market; Redis, Memcached, NCache and so on. Even Cloud providers like AWS offers managed distributed caching solutions – ElastiCache for Memcached or Redis.
Using SQL Server as Backing Store
dotnetcore provides a simple Distributed SQL Server Cache implementation to connect to an SQL Server database and use it as a backing store for the cache. Components use IDistributedCache interface to Get or Set data into the cache, while internally the data is written onto the SQL Server database.
All the cached content is stored in a table, and the caching library internally puts and fetches records from this table configured.
How to configure SQL Server for Caching
To demonstrate how this works, let’s begin by creating an SQL Server database and configuring it to be used as a backing store for the cache. dotnetcore provides us with a tool that can configure a given database for caching.
Let’s start by installing dotnet-sql-cache tool. This installation is a one-time step.
> dotnet tool install --global dotnet-sql-cache
Once installed, we can then run the below command which create a Table inside the given database for storing cached data. Keep in mind, you need to provide the name of an existing database, as the tool won’t create a database for you.
> dotnet sql-cache create "Data Source=(localdb)MSSQLLocalDB;Initial Catalog=DistCache;Integrated Security=True;" dbo TestCache
You should get an output “Table and index were created successfully.” which means that a table “TestCache” is successfully created inside the database DistCache. To verify, we can log into the SQL Server and observe the newly created table.
Caching API data with IDistributedCache
To demonstrate how it works, let’s start by creating a simple Web API application. I’m using .NET 6 webapi template with dotnet CLI as below:
> dotnet new webapi --name SqlCachedNinja
Once the project is created, open it with Visual Studio (or VS Code) and install the package “Microsoft.Extensions.Caching.SqlServer” which adds the library for IDistributedCache implementation.
> dotnet add package Microsoft.Extensions.Caching.SqlServer
Next, register the SQL Server database as a backing store for the Distributed Cache service inside Program.cs as below:
builder.Services.AddDistributedSqlServerCache(options =>
{
options.ConnectionString = builder.Configuration.GetConnectionString(
"DistCache_ConnectionString");
options.SchemaName = "dbo";
options.TableName = "TestCache";
});
The AddDistributedSqlServerCache() method takes in a predicate, where we provide the ConnectionString, the TableName and the SchemaName (which is dbo in our case).
The Connection String is same as the one we used in the command earlier – it now sits inside the appsettings JSON as below:
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft.AspNetCore": "Warning"
}
},
"ConnectionStrings": {
"DistCache_ConnectionString": "Data Source=(localdb)\MSSQLLocalDB;Initial Catalog=DistCache;Integrated Security=True;"
}
}
Finally, to consume and work with the cache, we can inject the IDistributedCache service inside our components and put or get objects from the cache.
For example, I will alter the default WeatherForecastController class to use caching for fetching and returning the temperatures as below:
using Microsoft.AspNetCore.Mvc;
using Microsoft.Extensions.Caching.Distributed;
using System.Text.Json;
namespace SqlCachedNinja.Controllers;
[ApiController]
[Route("[controller]")]
public class WeatherForecastController : ControllerBase
{
private static readonly string[] Summaries = new[]
{
"Freezing", "Bracing", "Chilly", "Cool", "Mild", "Warm", "Balmy", "Hot", "Sweltering", "Scorching"
};
private readonly ILogger<WeatherForecastController> _logger;
private readonly IDistributedCache _cache;
public WeatherForecastController(
ILogger<WeatherForecastController> logger,
IDistributedCache cache)
{
_logger = logger;
_cache = cache;
}
[HttpGet(Name = "GetWeatherForecast")]
public async Task<IEnumerable<WeatherForecast>> GetAsync()
{
var cached = await _cache.GetStringAsync("temperatures");
if (cached == null)
{
var result = Enumerable.Range(1, 5).Select(index => new WeatherForecast
{
Date = DateTime.Now.AddDays(index),
TemperatureC = Random.Shared.Next(-20, 55),
Summary = Summaries[Random.Shared.Next(Summaries.Length)]
}).ToArray();
await _cache.SetStringAsync(
"temperatures",
System.Text.Json.JsonSerializer.Serialize(result),
new DistributedCacheEntryOptions
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromMinutes(5),
SlidingExpiration = TimeSpan.FromSeconds(60)
});
return result;
}
else
{
return JsonSerializer.Deserialize<IEnumerable<WeatherForecast>>(cached);
}
}
}The below snippet sets the data inside the cache –
await _cache.SetStringAsync("temperatures",
System.Text.Json.JsonSerializer.Serialize(result),
new DistributedCacheEntryOptions {
AbsoluteExpirationRelativeToNow = TimeSpan.FromMinutes(5),
SlidingExpiration = TimeSpan.FromSeconds(60)
});The SetStringAsync() method is one of the methods provided by IDistributedCache to access data. The other methods include –
- Get() / GetAsync() for returning as byte array
- GetString() / GetStringAsync() for returning as strings
- Set() / SetAsync() for storing as byte array
- SetString() / SetStringAsync() for storing as strings
There are two types of Expirations I set here –
- AbsoluteExpirationRelativeToNow sets an AbsoluteExpiration relative from the time of insertion – the data becomes stale and removed once beyond the time configured, no matter how many times accessed
- SlidingExpiration – its a relative expiration and it extends for some more time if the data is accessed atleast once within this time.
When I run this API and hit the GET endpoint twice, for the first call the data is produced and cached into the SQL Server backing table and on the second call the data from the table is returned instead of producing data again.
If we observe the table contents back in our database, we can see a new record added in the database.
The table looks like below:
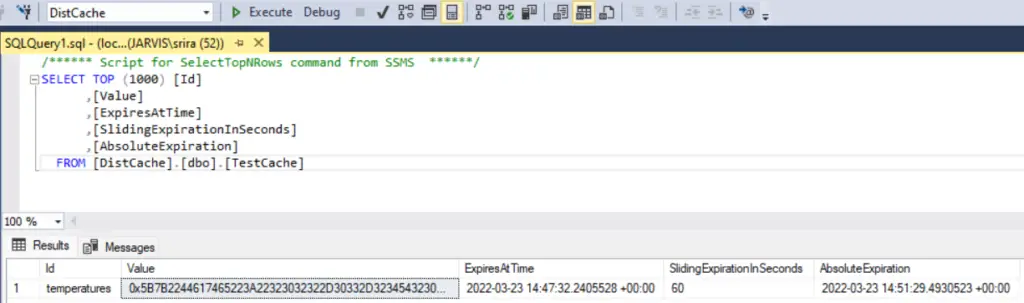
We can observe an entry with the key “temperatures” with value compacted and stored (probably to save space? not sure) along with the timestamps accordingly based on what we set in the code.
Conclusion and Final Thoughts
Distributed Cache externalizes and decouples the concept of caching from the application, which makes it an ideal choice for distributed architectures.
It can be implemented using many of the existing popular options such as Redis, Memcached, NCache and so on.

Found this article helpful? Please consider supporting!
We can also use an SQL Server database as a backing store for our caching mechanism, made simpler thanks to the generic IDistributedCache implementation provided by the dotnet SDK for developers.
Since all the caching implementation happens through the same interface, we can easily swap one cache with another as per our application requirements.
What do you think of this SQL Server caching approach?
Write down your thoughts below.

