
Table of Contents
What is Pagination?
Pagination is an important and interesting design choice made when the API needs to send a huge number of records to the client.
Pagination helps in creating partial data interactions in with little of chunks of data. It results in a system where the client is not overworked while processing the huge set of data thrown at it and the server is not overworked while processing the huge dataset to be passed down to the client.
The interaction happens over a common understanding over the number of records the client expects from the server and the server relays how many pages the client can expect from the server for loading the complete dataset.
The page size is kept at optimal so that the server can process quickly and the client can receive it without stressing the channel.
Pagination is more of a design choice than a functionality
In this article, let’s look at how we can implement an API that employs pagination in a simple way using ASP.NET Core and Entity Framework Core for the database interaction.
Building a Paginated Web API
To demonstrate how pagination works, let’s design a Posts API which has a single GET call that returns all the Posts available in the database.
Since this is a Posts API, we can expect that the data can grow in size over the time leading to possible performance issues. To avoid this, we’re going to design our GET API so that it sends out paginated data.
The API receives two inputs from the client – the pageNumber and the pageSize. The pageSize represents the number of records the client expects per page and the pageNumber is the current page going by the size of the records each page consists of.
Designing the Solution
Our Posts API solution follows an Onion Architecture with well-defined Core, Persistence and API layers. Core contains the contracts and services, the Persistence contains the database implementations and the API contains the API controllers.
The below commands let us create projects for API and Core layers and then add them both to a Solution file.
dotnet new classlib --name PagedNinja.Core
dotnet new classlib --name PagedNinja.Persistence
dotnet new webapi --name PagedNinja.Web
dotnet new sln --name PagedNinja
dotnet sln PagedNinja add ./PagedNinja.Core/PagedNinja.Core.csproj
dotnet sln PagedNinja add ./PagedNinja.Persistence/PagedNinja.Persistence.csproj
dotnet sln PagedNinja add ./PagedNinja.Web/PagedNinja.Web.csproj
Installing Dependencies
Once we’re done with the project setup, let’s install the necessary libraries for the database interaction. In this example, we’re going to use SQLite as our database so we’d install packages accordingly. We’d use Entity Framework Core as the mapping layer between SQLite db and our project.
> sqlite3
## create new db file in the API project directory
sqlite> .open app.db
We’ll use Entity Framework Core Code-First approach to connect to our database. Meaning we’ll have our migrations prepared in our codebase and update database accordingly. The Persistence layer contains all the nuget packages related to it.
Post installing libraries, our layers look like below:
#Core.csproj#
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>net6.0</TargetFramework>
</PropertyGroup>
</Project>
#Persistence Layer#
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>net6.0</TargetFramework>
<ImplicitUsings>enable</ImplicitUsings>
<Nullable>enable</Nullable>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.EntityFrameworkCore.Tools" Version="6.0.1">
<PrivateAssets>all</PrivateAssets>
<IncludeAssets>runtime; build; native; contentfiles; analyzers; buildtransitive</IncludeAssets>
</PackageReference>
<PackageReference Include="Microsoft.EntityFrameworkCore.Design" Version="6.0.1">
<PrivateAssets>all</PrivateAssets>
<IncludeAssets>runtime; build; native; contentfiles; analyzers; buildtransitive</IncludeAssets>
</PackageReference>
<PackageReference Include="Microsoft.Extensions.Logging.Console" Version="6.0.0" />
<PackageReference Include="Microsoft.EntityFrameworkCore.Sqlite" Version="6.0.1" />
</ItemGroup>
<ItemGroup>
<ProjectReference Include="..PagedNinja.CorePagedNinja.Core.csproj" />
</ItemGroup>
<ItemGroup>
<Folder Include="Migrations" />
</ItemGroup>
</Project>
#API Layer#
<Project Sdk="Microsoft.NET.Sdk.Web">
<PropertyGroup>
<TargetFramework>net6.0</TargetFramework>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.EntityFrameworkCore.Design" Version="6.0.1">
<PrivateAssets>all</PrivateAssets>
<IncludeAssets>runtime; build; native; contentfiles; analyzers; buildtransitive</IncludeAssets>
</PackageReference>
<PackageReference Include="Swashbuckle.AspNetCore" Version="5.6.3" />
</ItemGroup>
<ItemGroup>
<ProjectReference Include="..PagedNinja.CorePagedNinja.Core.csproj" />
<ProjectReference Include="..PagedNinja.PersistencePagedNinja.Persistence.csproj" />
</ItemGroup>
</Project>
How to setup DbContext and Repositories
We’d be working with Posts table from the database, so we’d have our entity class Post as below:
namespace PagedNinja.Core.Data.Entities
{
public class Post
{
[Key]
public int Id { get; set; }
public string Title { get; set; }
public string Content { get; set; }
public string Permalink { get; set; }
public DateTime CreatedOn { get; set; }
}
}
The database context class that maps this entity to the database, looks as below:
namespace PagedNinja.Persistence.Data
{
public class MyBlogContext : DbContext
{
public MyBlogContext(DbContextOptions options) : base(options)
{
}
public DbSet<Post> Posts { get; set; }
}
}Finally, the context is registered in the Startup class as below:
services.AddDbContext<MyBlogContext>(options =>
{
options.UseSqlite("Data Source=app.db");
});The abstract IPostsRepository defines the methods through which the API layer queries from the underlying database.
namespace PagedNinja.Core.Data.Repositories
{
public interface IPostsRepository
{
PaginatedPost GetPosts(int page = 1, int postsPerPage = 10);
Post Add(Post post);
int Count();
}
}A DataService wraps the instance to the IPostsRepository and exposes it.
namespace PagedNinja.Core.Data.Services
{
public interface IDataService
{
IPostsRepository Posts { get; }
void SaveChanges();
}
}Designing API to receive Page Numbers
As mentioned before, the client would pass the pageNumber and the pageSize to the API and the API would act accordingly. For this we design the API method as below:
namespace PagedNinja.Web.Controllers
{
[Route("api/[controller]")]
[ApiController]
public class PostsController : ControllerBase
{
private readonly IDataService _db;
public PostsController(IDataService db)
{
_db = db;
}
[HttpGet]
public PaginatedPost Get([FromQuery] QueryParams qp)
{
return _db.Posts.GetPosts(qp.Page, qp.PostsPerPage);
}
}
}The QueryParams type is binded from the query parameters by decorating with a FromQuery decorator. The class looks like below:
namespace PagedNinja.Core.Models
{
public class QueryParams
{
private const int _maxPageSize = 50;
private int _page = 10;
public int Page { get; set; } = 1;
public int PostsPerPage
{
get
{
return _page;
}
set
{
if (value > _maxPageSize) _page = _maxPageSize;
else _page = value;
}
}
}
}This class manages the validation logic of the pageSize being passed over to the API. The validation here ensures that the client doesn’t send too big a number on the pageSize for the API to handle. The max number of records per page is capped at 50, which is a reasonable set.
The controller endpoint passes the parameters to the Persistence implementation of the IPostsRepository which connects to the database and returns a paginated result.
How to implement Repository for Pagination
The PostsRepository class implements the IPostRepository interface and has a single method GetPosts() which receives the pageNumber and the pageSize and returns a PaginatedPost object, that contains the data as well as the meta information for the client.
namespace PagedNinja.Persistence.Data.Repositories
{
public class PostsRepository : IPostsRepository
{
private readonly MyBlogContext _context;
public PostsRepository(MyBlogContext context)
{
_context = context;
}
public Post Add(Post post)
{
_context.Posts.Add(post);
return post;
}
public int Count()
{
return _context.Posts.Count();
}
public PaginatedPost GetPosts(
int page = 1, int postsPerPage = 10)
{
return PaginatedPost.ToPaginatedPost(
_context.Posts.OrderBy(x => x.Id), page, postsPerPage);
}
}
}
The Pagination Logic
In the above class implementation, the Repository calls on the database for the posts list and then passes it to the static method ToPaginatedPost() inside the PaginatedPost class where the paging happens.
The PaginatedPost class looks like below:
namespace PagedNinja.Core.Models
{
public class PaginatedPost
{
public PaginatedPost(
IEnumerable<Post> items, int count, int pageNumber, int postsPerPage)
{
PageInfo = new PageInfo
{
CurrentPage = pageNumber,
PostsPerPage = postsPerPage,
TotalPages = (int)Math.Ceiling(count / (double)postsPerPage),
TotalPosts = count
};
this.Posts = items;
}
public PageInfo PageInfo { get; set; }
public IEnumerable<Post> Posts { get; set; }
public static PaginatedPost ToPaginatedPost(
IQueryable<Post> posts, int pageNumber, int postsPerPage)
{
var count = posts.Count();
var chunk = posts.Skip((pageNumber - 1) * postsPerPage).Take(postsPerPage);
return new PaginatedPost(chunk, count, pageNumber, postsPerPage);
}
}
public class PageInfo
{
public bool HasPreviousPage
{
get
{
return (CurrentPage > 1);
}
}
public bool HasNextPage
{
get
{
return (CurrentPage < TotalPages);
}
}
public int TotalPages { get; set; }
public int CurrentPage { get; set; }
public int PostsPerPage { get; set; }
public int TotalPosts { get; set; }
}
}
The ToPaginatedPost() method receives the Posts collection and then chunks it using the Skip().Take() combination. These are built-in extension methods provided by LINQ. Once the chunk is made, it is passed to the constructor of the PaginatedPost instance where the meta information is constructed.
public PaginatedPost(
IEnumerable<Post> items, int count, int pageNumber, int postsPerPage)
{
Metadata = new Metadata
{
CurrentPage = pageNumber,
PostsPerPage = postsPerPage,
TotalPages = (int)Math.Ceiling(count / (double)postsPerPage),
TotalPosts = count
};
this.Posts = items;
}
How this works?
The TotalPages is calculated based on the postsPerPage the client expects and the total records that are available in the database for the given entity.
For example, if the database contains 1000 posts and the client requests 24 posts per page, the total pages formed are 1000/24 which closes to 42 (we are ceiling) with 41 pages having 24 records each and the last page having 16 records.
The Metadata and Posts properties are available in the PaginatedPost class and these are filled and the instance is sent out to the caller.
The PostsController invokes this via a DataService class which contains the PostsRepository instance.
namespace PagedNinja.Persistence.Data.Services
{
public class DataService : IDataService
{
private readonly MyBlogContext _context;
public DataService(MyBlogContext context)
{
_context = context;
}
public IPostsRepository Posts => new PostsRepository(_context);
public void SaveChanges()
{
_context.SaveChanges();
}
}
}
The DataService implements the IDataService and is registered as a Scoped Service inside the dotnet core DI.
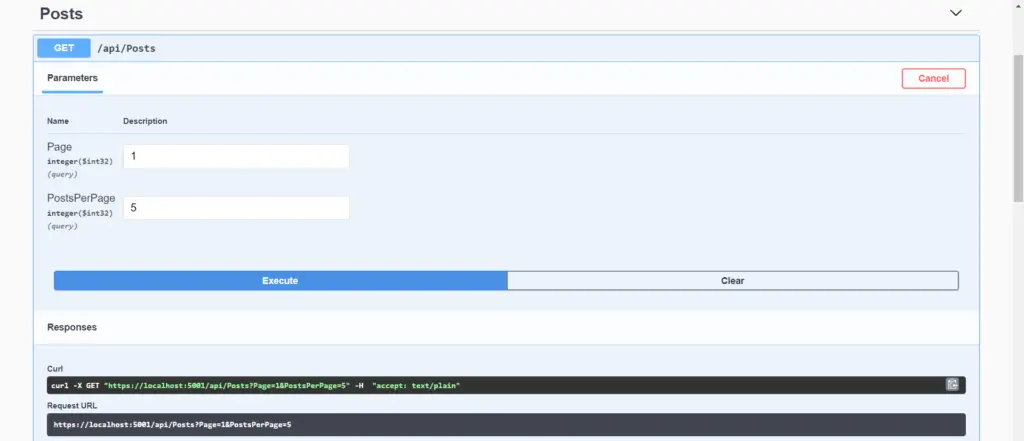
When we run the project with API as the startup project, we see that in the Swagger we have two parameters the endpoint expects “page” and “postsPerPage”. When we pass in the parameters, the API fetches the records according to the requested pageSize and returns the chunk.
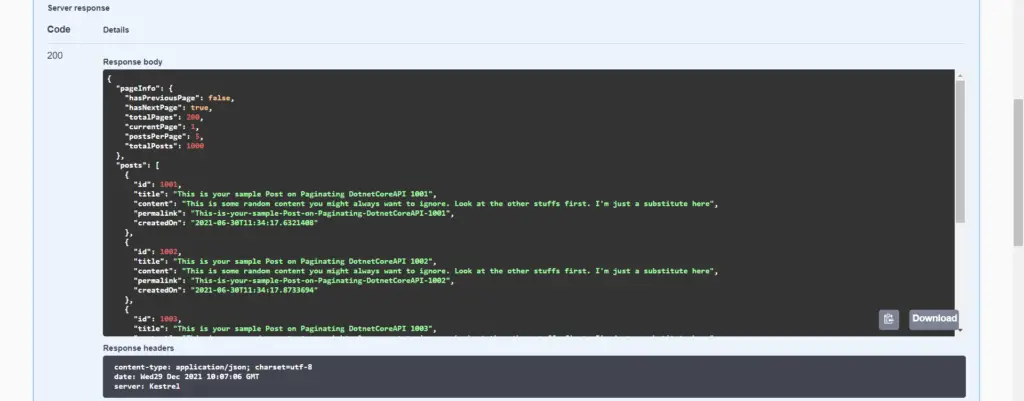
Analyzing the Query Performance
If we look at the query, we’re passing in the posts collection along with an OrderBy clause (context.Posts.OrderBy(x => x.Id)) but doesn’t that mean we’re calling up the entire dataset from the table? It doesn’t, because we’re passing an IQueryable to the PaginatedPost where we’re adding more filters to the dataset (Skip() and Take()) the underlying query which is executed over the database looks like below:
Executed DbCommand (1ms) [Parameters=[@__p_1='?', @__p_0='?'], CommandType='Text', CommandTimeout='30']
SELECT "p"."Id", "p"."Content", "p"."CreatedOn", "p"."Permalink", "p"."Title"
FROM "Posts" AS "p"
ORDER BY "p"."Id"
LIMIT @__p_1 OFFSET @__p_0This is lot better and faster than calling out all the records and filtering on them. This approach we’re following is called “Lazy-Evaluation” which happens due to the presence of the IQueryable

Found this article helpful? Please consider supporting!
Conclusion
Pagination can be a huge performance boost when implemented properly. It helps keep the back-end lighter and also results in a more intuitive and great user experience.
ASP.NET Core together with Entity Framework Core can make pagination easy with the LINQ extension methods at the disposal. Like mentioned before, Pagination is more of a design choice than a functional implementation. So it varies from application to application.
The code snippets used in this article are a part of a sample boilerplate project called PagedNinja. It helps understand designing pagination better and follows all coding best practices.
Please do leave a star if you find the repository helpful.


